檢視原始碼 Erlang 垃圾收集器
Erlang 使用追蹤式垃圾收集器來管理動態記憶體。更精確地說,它是一個針對每個進程的分代半空間複製收集器,使用 Cheney 的複製收集演算法,以及一個全域大型物件空間。(請參閱 參考文獻中的 C. J. Cheney。)
概觀
每個 Erlang 進程都有自己的堆疊和堆積,它們被分配在同一個記憶體區塊中,並朝彼此的方向增長。當堆疊和堆積相遇時,會觸發垃圾收集器並回收記憶體。如果沒有回收足夠的記憶體,堆積將會擴大。
建立資料
透過評估表達式,在堆積上建立 Term。Term 主要有兩種型別:立即 Term,它們不需要堆積空間(小型整數、原子、PID、port ID 等),以及 cons 或 封箱 Term(tuple、大型數字、二進位等),它們需要堆積空間。立即 Term 不需要任何堆積空間,因為它們被嵌入到包含的結構中。
讓我們來看一個範例,該範例返回一個帶有新建立資料的 tuple。
data(Foo) ->
Cons = [42|Foo],
Literal = {text, "hello world!"},
{tag, Cons, Literal}.在這個範例中,我們首先建立一個新的 cons cell,其中包含一個整數和一個帶有一些文字的 tuple。然後建立一個大小為三的 tuple,將其他值與一個原子標籤包裝在一起並返回。
在堆積上,tuple 為每個元素以及標頭需要一個字元組大小。Cons cell 總是需要兩個字元組。將這些加在一起,我們得到 tuple 的七個字元組和 cons cell 的 26 個字元組。字串 "hello world!" 是一個 cons cell 的列表,因此需要 24 個字元組。原子 tag 和整數 42 不需要任何額外的堆積記憶體,因為它們是立即的。將所有 Term 加在一起,此範例中所需的堆積空間應為 33 個字元組。
將此程式碼編譯為 beam 組件 ( erlc -S ) 會顯示實際發生的情況。
...
{test_heap,6,1}.
{put_list,{integer,42},{x,0},{x,1}}.
{put_tuple,3,{x,0}}.
{put,{atom,tag}}.
{put,{x,1}}.
{put,{literal,{text,"hello world!"}}}.
return.查看組譯器程式碼,我們可以發現三件事:此函數中的堆積需求僅為六個字元組,如 {test_heap,6,1} 指令所示。所有分配都組合到單個指令中。大部分資料 {text, "hello world!"} 是一個字面值。字面值,有時稱為常數,不會在函數中分配,因為它們是模組的一部分,並且在載入時分配。
如果堆積上沒有足夠的空間來滿足 test_heap 指令的記憶體請求,則會啟動垃圾收集。它可能會在 test_heap 指令中立即發生,或者可能會延遲到稍後的時間,具體取決於進程處於什麼狀態。如果延遲垃圾收集,則任何需要的記憶體都將在堆積片段中分配。堆積片段是年輕堆積的一部分的額外記憶體區塊,但不會分配在 Term 通常所在的連續區域中。有關更多詳細資訊,請參閱年輕堆積。
收集器
Erlang 具有複製半空間垃圾收集器。這意味著在執行垃圾收集時,Term 會從一個稱為來源空間的獨立區域複製到一個新的乾淨區域,稱為目標空間。收集器首先掃描根集合(堆疊、暫存器等)。
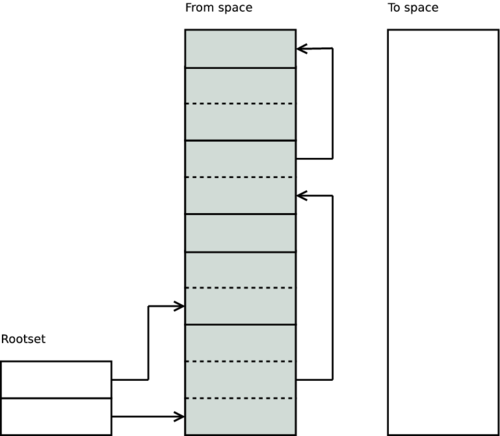
它會追蹤從根集合到堆積的所有指標,並逐字元組地將每個 Term 複製到目標空間。
複製標頭字元組後,會在其中破壞性地放置一個移動標記,指向目標空間中的 Term。任何指向已移動 Term 的其他 Term 都會看到此移動標記,並複製參照指標。例如,如果我們有以下 Erlang 程式碼
foo(Arg) ->
T = {test, Arg},
{wrapper, T, T, T}.在堆積上只有一個 T 副本,並且在垃圾收集期間,只有第一次遇到 T 時才會複製它。
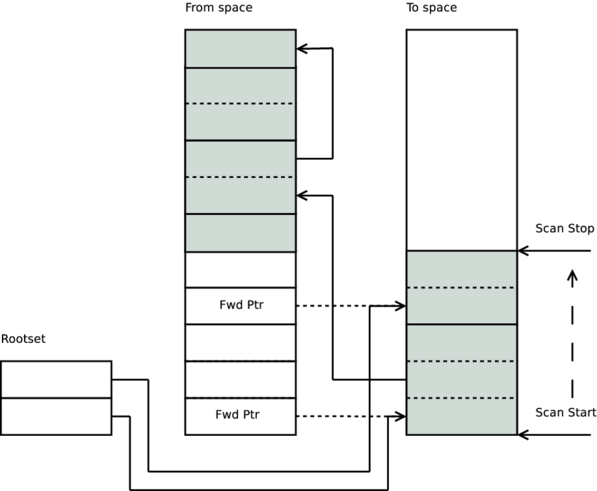
複製根集合參照的所有 Term 後,收集器會掃描目標空間,並複製這些 Term 參照的所有 Term。在掃描時,收集器會逐步執行目標空間上的每個 Term,並且任何仍然參照來源空間的 Term 都會複製到目標空間。某些 Term 包含非 Term 資料(例如堆積上二進位的有效負載)。當收集器遇到這些值時,只會簡單地跳過。
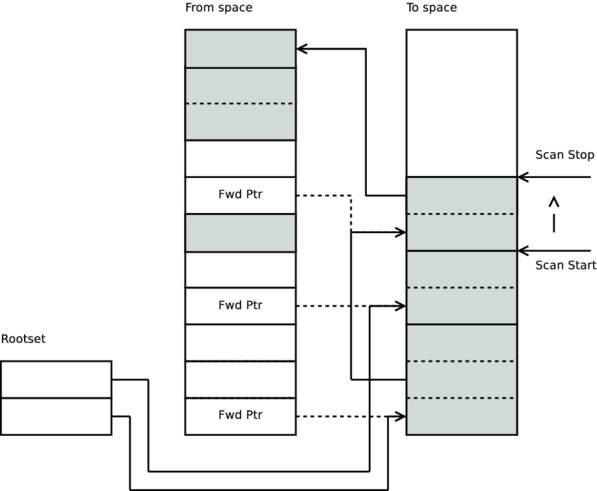
我們可以到達的每個 Term 物件都會被複製到目標空間,並儲存在掃描停止線的頂部,然後掃描停止會移動到最後一個物件的結尾。
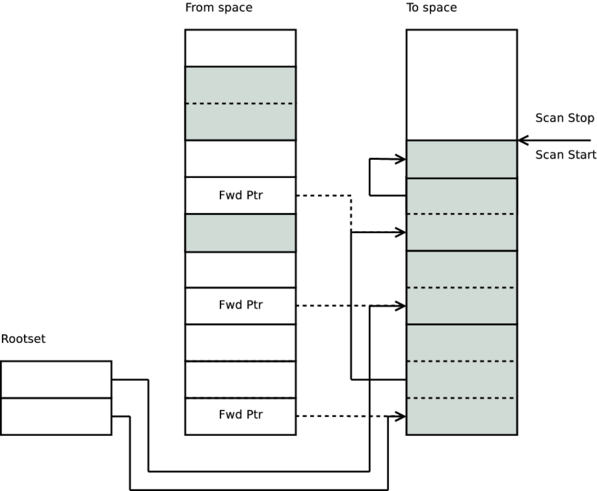
當掃描停止標記趕上掃描開始標記時,垃圾收集就完成了。此時,我們可以釋放整個來源空間,從而回收整個年輕堆積。
分代垃圾收集
除了上述收集演算法外,Erlang 垃圾收集器還提供分代垃圾收集。會使用一個稱為舊堆積的額外堆積,用於儲存長期存在的資料。原始堆積稱為年輕堆積,有時也稱為分配堆積。
考慮到這一點,我們可以再次查看 Erlang 的垃圾收集。在複製階段,如果它低於高水位標記,則應複製到年輕目標空間的任何內容都將複製到舊目標空間。

高水位標記放置在上一個垃圾收集(在概觀中描述)結束的位置,並且我們引入了一個稱為舊堆積的新區域。在執行常規垃圾收集傳遞時,任何位於高水位標記以下的 Term 都會複製到舊的目標空間,而不是年輕的。
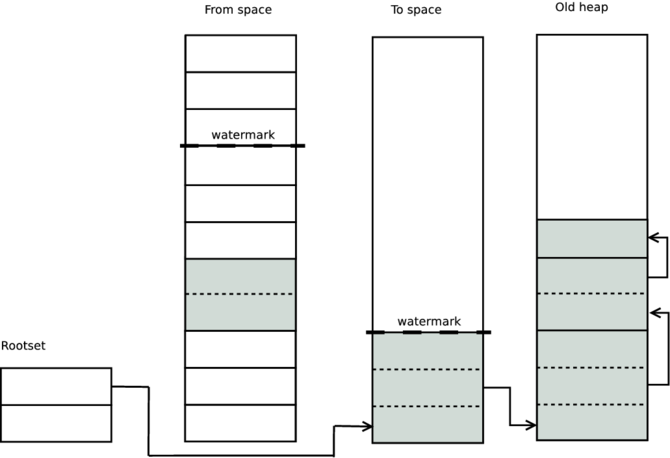
在下一次垃圾收集時,將忽略任何指向舊堆積的指標,並且不會掃描這些指標。這樣,垃圾收集器不必掃描長期存在的 Term。
分代垃圾收集旨在以記憶體為代價來提高效能。實現這一點是因為在大多數垃圾收集中僅考慮年輕的較小堆積。
分代假設預測,大多數 Term 傾向於早逝(請參閱參考文獻中的 D. Ungar),並且對於像 Erlang 這樣的不可變語言,年輕的 Term 甚至比其他語言中的 Term 死得更快。因此,對於大多數使用模式,新堆積中的資料將在分配後很快消失。這很好,因為它限制了複製到舊堆積的資料量,而且還因為使用的垃圾收集演算法與堆積上存在的有效資料量成正比。
這裡需要注意的一個關鍵問題是,年輕堆積上的任何 Term 都可以參照舊堆積上的 Term,但是舊堆積上的任何 Term 都不能參照年輕堆積上的 Term。這是由於複製演算法的性質所致。舊堆積 Term 參照的任何內容都不會包含在參照樹、根集合及其跟隨者中,因此不會被複製。如果是這樣,資料將會丟失,並且硫磺火將升起覆蓋地球。幸運的是,這對 Erlang 來說是自然而然的,因為 Term 是不可變的,因此不能在舊堆積上修改指標以指向年輕堆積。
要從舊堆積回收資料,會在收集期間包含年輕和舊堆積,並將其複製到一個公共的目標空間。然後,會釋放年輕和舊堆積的來源空間,並且此過程將從頭開始重新開始。當高水位標記下的區域大小大於舊堆積的空閒區域大小時,會觸發這種垃圾收集,稱為完整掃描。也可以透過手動呼叫 erlang:garbage_collect() 或透過執行 spawn_opt(fun(),{fullsweep_after, N}) 設定的年輕垃圾收集限制來觸發,其中 N 是在強制對年輕和舊堆積進行垃圾收集之前要執行的年輕垃圾收集次數。
年輕堆積
年輕堆積或分配堆積,由概觀中所述的堆疊和堆積組成。但是,它還包括附加到堆積的任何堆積片段。所有堆積片段都被認為是高水位標記以上的部分,也是年輕世代的一部分。堆積片段包含不適合堆積或由另一個進程建立然後附加到堆積的 Term。例如,如果 BIF binary_to_term/1 建立的 Term 不適合當前堆積,並且沒有執行垃圾收集,則它將為該 Term 建立一個堆積片段,然後排程稍後進行垃圾收集。此外,如果將訊息傳送到進程,則有效負載可以放置在堆積片段中,並且當訊息在接收子句中匹配時,該片段會新增到年輕堆積。
此過程與 Erlang/OTP 19.0 之前的運作方式不同。在 19.0 之前,只有年輕堆積和堆疊所在的連續記憶體區塊被視為年輕堆積的一部分。堆積片段和訊息會立即複製到年輕堆積中,然後才能由 Erlang 程式檢查。19.0 中引入的行為在許多方面都更優越 - 最重要的是,它減少了必要的複製操作次數以及垃圾收集的根集合。
調整堆積大小
如概觀中所述,堆積的大小會增長以容納更多資料。堆積分為兩個階段增長,首先使用從 233 個字元組開始的費波那契數列的變體。然後,當約為 1 百萬個字元組時,堆積僅以20% 的增量增長。
在兩種情況下,年輕堆積會增長
- 如果堆積 + 訊息和堆積片段的總大小超過當前的堆積大小。
- 如果在完整掃描後,有效物件的總量大於 75%。
在兩種情況下,年輕堆積會縮小
- 如果在年輕收集後,有效物件的總量少於堆積的 25% 且年輕堆積「很大」。
- 如果在完整掃描後,有效物件的總量少於堆積的 25%。
舊堆積始終比年輕堆積在堆積增長階段領先一步。
字面值
當進行垃圾回收(年輕代或老年代)時,所有字面值都會保留在原地,不會被複製。在進行垃圾回收時,為了判斷一個詞彙是否應該被複製,會使用以下虛擬碼:
if (erts_is_literal(ptr) || (on_old_heap(ptr) && !fullsweep)) {
/* literal or non fullsweep - do not copy */
} else {
copy(ptr);
}erts_is_literal 檢查在不同的架構和作業系統上的運作方式不同。
在允許映射未保留虛擬記憶體區域的 64 位元系統上(大多數作業系統,除了 Windows),會映射一個大小為 1 GB(預設值)的區域,然後將所有字面值放置在該區域內。然後,要判斷某個東西是否為字面值,只需進行兩個快速的指標檢查即可。這個系統依賴於一個事實:尚未被觸及的記憶體頁面不會佔用任何實際空間。因此,即使映射了 1 GB 的虛擬記憶體,也只會在 RAM 中分配實際需要用於字面值的記憶體。字面值區域的大小可以透過 +MIscs erts_alloc 選項進行配置。
在 32 位元系統上,沒有足夠的虛擬記憶體空間來為字面值分配 1 GB,因此會根據需求創建 256 KB 大小的字面值區域,並使用整個 32 位元記憶體空間的卡片標記位元陣列來判斷一個詞彙是否為字面值。由於總記憶體空間只有 32 位元,卡片標記位元陣列只有 256 個字的大小。在 64 位元系統上,相同的位元陣列必須有 1 兆字的大小,因此這種技術只在 32 位元系統上可行。在陣列中查找比在 64 位元系統中僅進行指標檢查要稍微昂貴一些,但並非極度昂貴。
在 64 位元 Windows 上,由於 erts_alloc 無法進行未保留的虛擬記憶體映射,會使用 Erlang 詞彙物件中的特殊標籤來判斷某個東西是否為字面值。這種方式非常便宜,但是,該標籤僅在 64 位元機器上可用,而且未來可以利用該標籤進行許多其他良好的優化(例如,更緊湊的列表實現),因此不會在不需要它的作業系統上使用。
這種行為與 Erlang/OTP 19.0 之前的運作方式不同。在 19.0 之前,字面值檢查是通過檢查指標是否指向年輕代或老年代堆積區塊來完成的。如果沒有,則認為它是字面值。這導致了相當大的開銷和奇怪的記憶體使用情況,因此在 19.0 中被移除。
二元堆積區
二元堆積區作為一個大型物件空間,用於存放大於 64 位元組的二元詞彙(以下稱為堆外二元詞彙)。二元堆積區採用參考計數,並且在行程堆積區中儲存指向堆外二元詞彙的指標。為了追蹤何時遞減堆外二元詞彙的參考計數器,會將一個連結列表(MSO - 標記和清除物件列表)與 fun 和外部參照以及堆外二元詞彙一起編織到堆積區中。在完成垃圾回收後,會掃描 MSO 列表,並且任何沒有在標頭字中寫入移動標記的堆外二元詞彙,其參考計數器會被遞減,並可能被釋放。
MSO 列表中的所有項目都按照它們添加到行程堆積區的時間順序排序,因此在進行次要垃圾回收時,MSO 清除器只需要掃描到遇到一個位於老年代堆積區上的堆外二元詞彙即可。
虛擬二元堆積區
每個行程都有一個與之關聯的虛擬二元堆積區,其大小等於該行程目前參考的所有堆外二元詞彙的大小。虛擬二元堆積區也有一個限制,並且會根據行程如何使用堆外二元詞彙而增長和縮小。二元堆積區和詞彙堆積區使用相同的增長和縮小機制,因此首先使用費波納契數列,然後增長 20%。
虛擬二元堆積區的存在是為了在有可能可以回收大量堆外二元詞彙資料時,更早地觸發垃圾回收。這種方法並不能捕獲所有二元記憶體沒有及時釋放的問題,但確實捕獲了很多問題。
訊息
訊息可以在不同的時間成為行程堆積區的一部分。這取決於如何配置行程。我們可以透過 process_flag(message_queue_data, off_heap | on_heap) 設定每個行程的行為,或者可以使用選項 +hmqd 在啟動時為所有行程設定預設值。
這些不同的配置有什麼作用?我們應該在什麼時候使用它們?讓我們先來看看一個 Erlang 行程向另一個行程發送訊息時會發生什麼。發送行程需要執行幾個動作:
接收行程的行程標誌 message_queue_data 控制了發送行程在步驟 2 中的訊息分配策略,以及垃圾回收器如何處理訊息資料。
上面的程序與 19.0 之前的運作方式不同。在 19.0 之前,沒有配置選項,其行為始終與 19.0 中的 on_heap 選項非常相似。
訊息分配策略
如果設定為 on_heap,發送行程將首先嘗試直接在接收行程的年輕代堆積區塊上分配訊息的空間。這並非總是可行,因為它需要取得接收行程的 *主鎖定* 。當行程正在執行時,也會持有主鎖定。因此,在一個密集協作的系統中,發生鎖定衝突的可能性很高。如果發送行程無法取得主鎖定,則會為訊息創建一個堆積區片段,並將訊息有效負載複製到該片段上。使用 off_heap 選項時,發送行程始終會為發送到該行程的訊息創建堆積區片段。
當試圖找出要使用哪個策略時,會出現許多不同的權衡。
使用 off_heap 看起來是一種取得更具可擴展性的系統的好方法,因為你在主鎖定上的競爭非常少,但是,分配一個堆積區片段比在接收行程的堆積區上分配更昂貴。因此,如果不太可能發生競爭,則嘗試直接在接收行程的堆積區上分配訊息會更有效率。
使用 on_heap 會強制所有訊息成為年輕代堆積區的一部分,這將增加垃圾回收器必須移動的資料量。因此,如果在處理大量訊息時觸發垃圾回收,它們將被複製到年輕代堆積區。這反過來又會導致訊息很快被晉升到老年代堆積區,從而增加其大小。這可能好也可能壞,具體取決於行程的具體操作。較大的老年代堆積區意味著年輕代堆積區也會較大,這反過來又意味著在處理訊息佇列時觸發的垃圾回收次數會減少。這將暫時提高行程的吞吐量,但會以更高的記憶體使用量為代價。但是,如果在消耗所有訊息後,行程進入接收較少訊息的狀態。那麼,可能要經過很長時間才會發生下一次完整掃描垃圾回收,並且老年代堆積區上的訊息將會一直存在直到那時。因此,雖然 on_heap 可能比其他模式更快,但它會在更長的時間內使用更多記憶體。這種模式是傳統模式,與 Erlang/OTP 19.0 之前處理訊息佇列的方式幾乎相同。
這些策略中哪一個最好,很大程度上取決於行程正在執行什麼操作以及它如何與其他行程互動。因此,與往常一樣,對應用程式進行效能分析,看看它在不同選項下的行為如何。
參考文獻
C. J. Cheney. 一種非遞迴列表壓縮演算法. Commun. ACM, 13(11):677–678, 1970 年 11 月.
D. Ungar. 生成式掃描:一種非中斷式高效能儲存回收演算法. SIGSOFT Softw. Eng. Notes, 9(3):157–167, 1984 年 4 月.