檢視原始碼 BeamAsm,Erlang JIT
BeamAsm 提供了在 x86-64 和 aarch64 上將 Erlang BEAM 指令在載入時轉換為原生碼的功能。這讓載入器能夠消除任何指令分派的額外開銷,並根據其引數型別來客製化每個指令。
BeamAsm 幾乎不做跨指令最佳化,而且 x 和 y 暫存器陣列的工作方式與解譯 BEAM 指令時相同。這讓 Erlang 執行時系統基本上保持不變,除了需要處理載入的 BEAM 指令的地方,例如程式碼載入、追蹤和其他一些地方。
BeamAsm 使用 asmjit 來在執行時產生原生碼。只使用了 asmjit 的 Assembler API 的一小部分。目前 asmjit 僅支援 x86 32/64 位元和 aarch64 組譯器。
載入程式碼
程式碼的載入方式與解譯器載入的方式非常相似。每個 beam 檔案都會被解析,然後透過 beam_makeops 中描述的轉換進行最佳化。BeamAsm 中使用的轉換比解譯器的轉換簡單得多,因為解譯器的轉換大多只是為了消除指令分派的額外開銷。
然後,每個指令都會使用 jit/$ARCH/instr_*.cpp 檔案中的 C++ 函式進行編碼。例如
void BeamModuleAssembler::emit_is_nonempty_list(const ArgVal &Fail, const ArgVal &Src) {
a.test(getArgRef(Src), imm(_TAG_PRIMARY_MASK - TAG_PRIMARY_LIST));
a.jne(labels[Fail.getLabel()]);
}asmjit 提供了從 C++ 函式呼叫到 x86 組語指令的相當直接的對應。上面的指令會測試 Src 暫存器中的值是否為非空列表,如果不是,則會跳到 fail 標籤。
相比之下,解譯器有 8 種這種實作的組合和特化,以盡量減少常見模式的指令分派額外開銷。
由 Erlang 編譯器完成的原始暫存器分配會用於管理值的存活狀態,而實體暫存器會靜態分配以保留必要的處理程序狀態。目前,這是 x86-64 上的靜態暫存器分配
rbx: ErtsSchedulerRegisters struct (contains x/float registers and some metadata)
rbp: Current frame pointer when `perf` support is enabled, otherwise this
is an optional save slot for the Erlang stack pointer when executing C
code.
r12: Active code index
r13: Current running process
r14: Remaining reductions
r15: Erlang heap pointer請注意,所有這些都是 System V 和 Windows ABI 下的被呼叫者儲存暫存器,這表示 BeamAsm 在進行 C 函式呼叫時永遠不必溢出這些暫存器。
呼叫者儲存暫存器會作為指令內的暫存暫存器使用,但通常不會在它們之間傳遞資訊。對於一些頻繁的指令序列,例如元組匹配,會進行跨指令最佳化,以避免在每個 get_tuple_element 指令中提取元組的基底位址。
縮減程式碼大小和載入時間
解譯器的優勢之一是它用於載入程式碼的記憶體相對較少。這是因為每個載入指令的實作都是共用的,只有指令的引數會有所不同。使用盡可能少的記憶體有很多優點:使用的記憶體較少、載入時間縮短、快取命中率較高。
在 BeamAsm 中,我們需要實現類似的目標,因為模組的載入時間幾乎與其使用的記憶體量呈線性關係。早期的 BeamAsm 原型使用約為解譯器兩倍的程式碼記憶體,而目前的版本則多使用了約 10%。這是如何實現的?
在 BeamAsm 中,我們大量使用共用程式碼片段,以盡可能多地發出程式碼作為全域共用片段,而不是不必要地複製程式碼。例如,return 指令看起來像這樣
Label yield = a.newLabel();
/* Decrement reduction counter */
a.dec(FCALLS);
/* If FCALLS < 0, jump to the yield-on-return fragment */
a.jl(resolve_fragment(ga->get_dispatch_return()));
a.ret();上面的程式碼不完全是發出的程式碼,但已足夠接近。要注意的是,用於執行上下文切換的程式碼永遠不會發出。相反,我們會跳到所有 return 指令共用的全域片段。這大大減少了每個模組必須發出的程式碼量。
執行 Erlang 程式碼
執行 BeamAsm 程式碼與執行解譯器非常相似,只是執行的是原生碼而不是解譯的程式碼。
我們必須調整 Erlang 堆疊的工作方式,才能在其上執行原生指令。雖然解譯器會使用堆疊插槽來儲存目前框架的返回位址 (在未使用時將其設定為 []),但原生程式碼僅保留足夠的空間,因為 x86 call 和 ret 指令在執行時會增加堆疊指標。
這只會影響目前的堆疊框架,而且除了兩個注意事項外,在功能上是相同的
在保留返回位址時,不得擲回例外狀況。
很難判斷例外狀況發生後堆疊將會在哪裡結束;如果我們在目前的堆疊框架中當機,返回位址將不會在堆疊上,但如果我們在呼叫的函式中當機,則會存在。區分這些情況變得相當複雜,因此我們決定在擲回例外狀況時,必須使用返回位址。
emit_handle_error會為您處理此問題,而預設情況下,已呼叫(而非跳轉)的共用片段會滿足此要求。垃圾收集需要考慮返回位址。
如果我們要建立一個術語,我們必須確保有足夠的空間來儲存此術語和潛在的返回位址,否則下一個
call會覆蓋該術語。這會在emit_gc_test中處理,而且您通常不需要考慮它。
除了上述內容之外,我們還會確保堆疊上始終至少有 S_REDZONE 個空閒字,因此即使我們沒有堆疊框架,也可以呼叫共用片段或追蹤處理常式。這只是一個保留,並不會影響堆疊的工作方式,而且為了進行垃圾收集,儲存在那裡的所有值都必須是有效的 Erlang 術語。
框架指標
為了協助除錯器和取樣分析器,我們支援使用原生框架指標執行 Erlang 程式碼。在撰寫本文時,這只會與 perf 支援 (+JPperf true) 一起啟用,以節省堆疊空間,但我們可能會在未來新增一個旗標來明確啟用它。
啟用時,接續指標 (CP) 會有一個返回位址和一個指向先前 CP 的框架指標。CP 必須始終形成有效的鏈,而且當檢查堆疊時,擁有「一半」的 CP 是不合法的。
框架指標會在進入 Erlang 函式時推送,並在離開函式之前彈出,包括尾部呼叫,因為被呼叫者會立即在進入時推送框架指標。這會產生一些額外開銷,但可以避免我們針對每個函式擁有多個進入點,具體取決於它是尾部呼叫還是主體呼叫,一旦中斷點進入畫面,這將變得非常棘手。
執行 C 程式碼
由於 Erlang 堆疊可能非常小,因此當我們需要執行 C 程式碼時 (可能會需要更大的堆疊),我們必須切換到不同的堆疊。這是透過 emit_enter_runtime 和 emit_leave_runtime 完成的,例如
mov_arg(ARG4, NumFree);
/* Move to the C stack and swap out our current reductions, stack-, and
* heap pointer to the process structure. */
emit_enter_runtime<Update::eReductions | Update::eStack | Update::eHeap>();
a.mov(ARG1, c_p);
load_x_reg_array(ARG2);
make_move_patch(ARG3, lambdas[Fun.getValue()].patches);
/* Call `new_fun`, asserting that we're on the C stack. */
runtime_call<4>(new_fun);
/* Move back to the C stack, and read the updated values from the process
* structure */
emit_leave_runtime<Update::eReductions | Update::eStack | Update::eHeap>();
a.mov(getXRef(0), RET);Update 常數的所有組合都是合法的,但給予 emit_leave_runtime 的常數必須與給予 emit_enter_runtime 的常數相同。
追蹤和 NIF 載入
為了讓追蹤和 NIF 載入能夠運作,需要有一種方法來攔截任何函式呼叫。在解譯器中,這是透過重寫載入的 BEAM 程式碼來完成的,但在 BeamAsm 中,由於我們想要一種快速且精簡的方式來執行此操作,因此會更複雜。這個問題是透過在每個函式開頭發出以下程式碼來解決的(以下是 x86 變體)
0x0: short jmp 6 (address 0x8)
0x2: nop
0x3: relative near call to shared breakpoint fragment
0x8: actual code for function當程式碼開始執行時,它只會看到 short jmp 6 指令,它會跳過序言並直接開始執行程式碼。
當我們想要啟用特定的中斷點時,我們會將 jmp 目標設定為 1,這表示它會落在呼叫共用中斷點片段的地方。此片段會檢查此函式的 ErtsCodeInfo 中儲存的目前 breakpoint_flag,然後分別呼叫 erts_call_nif_early 和 erts_generic_breakpoint。
請注意,分支和 breakpoint_flag 的更新不需要是不可分割的:如果進程只看到這些更新中的一個,也沒關係,因為設定中斷點/載入 NIF 的程式碼並不依賴跳板在執行緒進度已取得之前處於作用中狀態。
AArch64 的解決方案類似。
更新程式碼
由於許多環境會強制執行 W^X,因此不一定可以直接寫入程式碼頁面。因此,我們會將程式碼對應兩次:一次是使用可執行頁面,另一次是使用可寫入頁面。由於它們由相同的記憶體支援,因此寫入可寫入頁面的內容會神奇地出現在可執行頁面中。
如果模組實例已先取消密封,則可以使用 erts_writable_code_ptr 函式來取得可寫入指標
for (i = 0; i < n; i++) {
const ErtsCodeInfo* ci_exec;
ErtsCodeInfo* ci_rw;
void *w_ptr;
erts_unseal_module(&modp->curr);
ci_exec = code_hdr->functions[i];
w_ptr = erts_writable_code_ptr(&modp->curr, ci_exec);
ci_rw = (ErtsCodeInfo*)w_ptr;
uninstall_breakpoint(ci_rw, ci_exec);
consolidate_bp_data(modp, ci_rw, 1);
ASSERT(ci_rw->gen_bp == NULL);
erts_seal_module(&modp->curr);
}如果沒有模組實例,則沒有可靠的方法來找出程式碼頁面的可寫入位址,而且我們依賴位址空間配置隨機化 (ASLR) 來使其難以猜測。在某些平台上,會透過保護可寫入區域免受寫入影響,直到模組已由 erts_unseal_module 取消密封,才能進一步增強安全性。
匯出追蹤
與解譯器不同,我們不會在匯出項目內執行程式碼,因為在面對 W^X 時,這樣做非常麻煩。啟用追蹤後,我們會改為指向一個會查看目前匯出項目並決定如何處理的片段。
這個程式碼片段在所有匯出入口之間共享,並且假設要操作的匯出入口位於特定暫存器中(撰寫時為 RET)。這表示所有遠端呼叫必須將匯出入口放置在該暫存器中,即使我們事先不知道該呼叫是遠端的,例如在呼叫函式時。
這在組譯器中很容易做到,並且 emit_setup_dispatchable_call 輔助函式可以很好地處理它,但是當從 C 程式碼中跳脫時,我們無法設定暫存器。當從 C 程式碼跳脫到匯出入口時,必須將 c_p->current 設定為所討論的匯出入口內的 ErtsCodeMFA,然後將 c_p->i 設定為 beam_bif_export_trap。
BIF_TRAP 巨集會為您處理此問題,因此您通常不需要考慮它。
每個檔案的說明
BeamAsm 實作位於 $ERL_TOP/erts/emulator/beam/jit 資料夾中。這些檔案是
asm_load.c- 用於載入程式碼的 BeamAsm 特定函式
beam_asm.h- 描述 C -> C++ API 的標頭檔
beam_jit_metadata.cpp- BeamAsm 的
gdb和 Linuxperf支援
- BeamAsm 的
load.h- 用於載入程式碼的 BeamAsm 特定標頭
$ARCH/beam_asm.hpp- 描述 BeamAsm 使用的結構和類別的標頭檔。
$ARCH/beam_asm.cpp- BeamAsm 初始化程式碼
- C -> C++ 介面函式。
$ARCH/generators.tab、$ARCH/predicates.tab、$ARCH/ops.tab- 指令的 BeamAsm 特定轉換。有關更多詳細資訊,請參閱 beam_makeops。
$ARCH/beam_asm_module.cpp- BeamAsm 模組程式碼產生器邏輯的程式碼
$ARCH/beam_asm_global.cpp- 多個指令使用的全域程式碼片段,例如錯誤處理程式碼。
$ARCH/instr_*.cpp- 依區域分組的個別指令實作
$ARCH/process_main.cpp- 主要處理迴圈的實作
Linux perf 支援
JIT 可以為 Linux 分析器 perf 提供符號,使其可以使用它來分析 Erlang 程式碼。根據使用的模式,perf 將提供類似於 eprof 或 fprof 的功能,但開銷要低得多(且可配置)。
您可以像這樣在 BeamAsm 上執行 perf
# Start Erlang under perf
perf record -- erl +JPperf true
# Record a running instance started with `+JPperf true` for 10s
perf record --pid $BEAM_PID -- sleep 10
# Record a running instance started with `+JPperf true` until interrupted
perf record --pid $BEAM_PID然後像平常使用 perf 一樣使用 perf report 查看結果。
當傳遞 +JPperf true 選項時,會啟用框架指標,因此您可以使用 perf record --call-graph=fp 來取得更多上下文,使結果類似於 fprof 的結果。這將為您提供純 Erlang 程式碼的精確呼叫圖,但在極少數情況下,它無法追蹤從 Erlang 到 C 程式碼再返回的轉換。perf record --call-graph=lbr 在這些情況下可能效果更好,但它在一般追蹤方面較差。
例如,您可以執行 perf 來分析 dialyzer 建置 PLT,如下所示
ERL_FLAGS="+JPperf true +S 1" perf record --call-graph=fp \
dialyzer --build_plt -Wunknown --apps compiler crypto erts kernel stdlib \
syntax_tools asn1 edoc et ftp inets mnesia observer public_key \
sasl runtime_tools snmp ssl tftp wx xmerl tools上面的程式碼使用 +S 1 執行,以使 perf 輸出更容易理解。如果您接著執行 perf report -f --no-children,您可能會得到類似於以下的結果
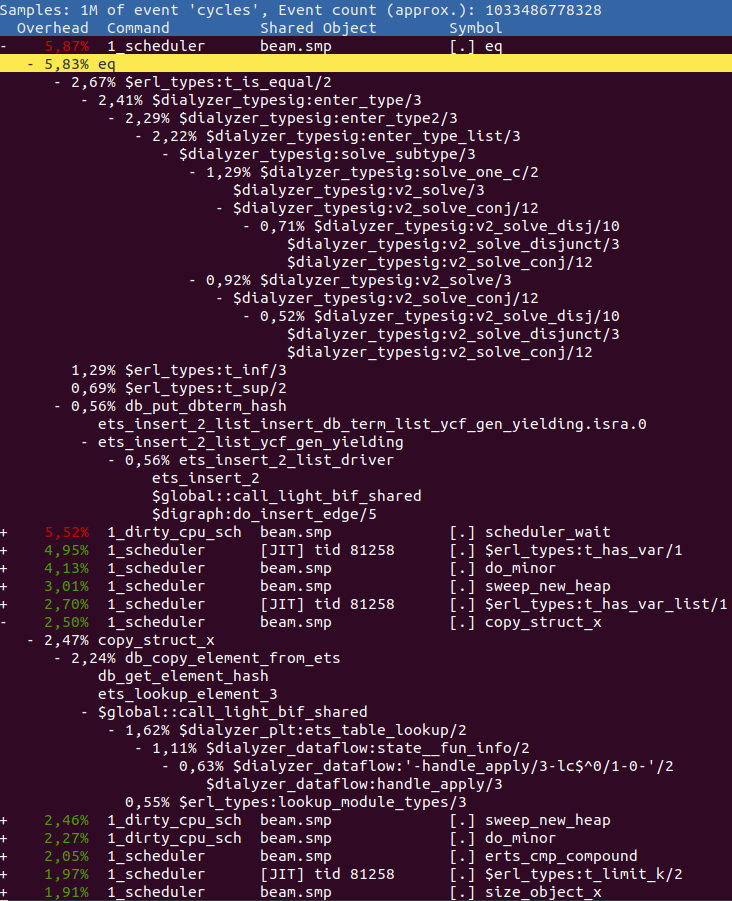
報告中的任何 Erlang 函式都以 $ 作為前綴,所有 C 函式都有其正常名稱。任何具有 $global:: 前綴的 Erlang 函式都指的是全域共享程式碼片段。
因此,在上面,我們可以觀察到我們花費最多時間在執行 eq,即比較兩個項。透過展開它並查看其父項,我們可以發現,對這個值貢獻最大的是函式 erl_types:t_is_equal/2。請檢視原始程式碼,看看您是否可以找出為何在此花費這麼多時間。
在 eq 之後,我們看到函式 erl_types:t_has_var/1,我們在其中花費了將近整個執行時間的 5%。再往下看,您可以看到 copy_struct_x,它是用於複製項目的函式。如果我們展開它以檢視父項,我們發現主要是 ets:lookup_element/3,透過 Erlang 函式 dialyzer_plt:ets_table_lookup/2 對此時間做出了貢獻。
火焰圖
您也可以從 perf 輸出建立火焰圖。火焰圖基本上只是查看與 perf report 輸出相同資料的另一種方式,但可以更輕鬆地與他人分享和操作,以提供專為您的需求量身定制的圖表。例如,如果我們使用所有排程器執行 dialyzer
## Run dialyzer with multiple schedulers
ERL_FLAGS="+JPperf true" perf record --call-graph=fp \
dialyzer --build_plt -Wunknown --apps compiler crypto erts kernel stdlib \
syntax_tools asn1 edoc et ftp inets mnesia observer public_key \
sasl runtime_tools snmp ssl tftp wx xmerl tools --statistics然後使用 Brendan Gregg 的 CPU 火焰圖網頁上找到的腳本,如下所示
## Collect the results
perf script > out.perf
## run stackcollapse
stackcollapse-perf.pl out.perf > out.folded
## Create the svg
flamegraph.pl out.folded > out.svg我們會得到類似於以下的圖表

您可以在這裡檢視較大的版本。它包含相同的資訊,但更容易與他人分享,因為它不需要可執行檔中的符號。
使用相同的資料,我們也可以產生一個圖表,其中使用 sed 合併了排程器設定檔資料
## Strip [0-9]+_ and/or _[0-9]+ from all scheduler names
## scheduler names changed in OTP26, hence two expressions
sed -e 's/^[0-9]\+_//' -e 's/^erts_\([^_]\+\)_[0-9]\+/erts_\1/' out.folded > out.folded_sched
## Create the svg
flamegraph.pl out.folded_sched > out_sched.svg
您可以在這裡檢視較大的版本。您可以進行許多不同的轉換,使圖表顯示您想要的内容。
註解 perf 函式
如果您想要能夠使用 perf annotate 功能(以及 perf report GUI 中的擴展註解功能),您需要在呼叫 perf record 時使用單調時鐘,即 perf record -k mono。因此,對於 dialyzer 執行,您應該執行以下操作
ERL_FLAGS="+JPperf true +S 1" perf record -k mono --call-graph=fp \
dialyzer --build_plt -Wunknown --apps compiler crypto erts kernel stdlib \
syntax_tools asn1 edoc et ftp inets mnesia observer public_key \
sasl runtime_tools snmp ssl tftp wx xmerl tools為了使用此記錄產生的 perf.data,您需要先像這樣呼叫 perf inject --jit
perf inject --jit -i perf.data -o perf.jitted.data然後您可以像這樣檢視註解函式
perf annotate -M intel -i perf.jitted.data erl_types:t_has_var/1或者在 perf report UI 中按下 a。然後您會得到類似於以下的内容
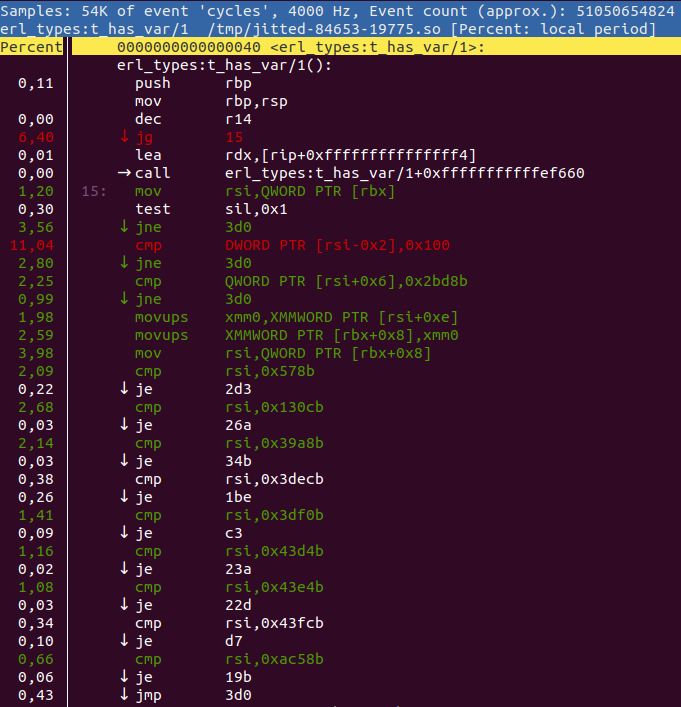
perf annotate 將在可能的情況下將列表與原始程式碼交錯。您可以使用 +{source,Filename} 或 +absolute_paths 編譯器選項來告訴 perf 在哪裡可以找到原始程式碼。
警告:呼叫
perf inject --jit將在/tmp/和~/.debug/tmp/中建立大量檔案。因此,請務必不時清理這些目錄,否則您可能會用完 inode。
在另一台主機上檢查 perf 資料
有時在目標機器上檢查錄製是不可能的或不希望的,這會變得有點棘手,因為 perf report 依賴於所有可用的符號。
若要在另一台機器上檢查錄製,您可以使用 perf archive 命令將所有需要的符號捆綁到一個封存中。這要求錄製使用 -k mono 旗標進行,並且已使用 perf inject --jit 進行處理
perf inject --jit -i perf.data -o perf.jitted.data
perf archive perf.jitted.data取得封存後,將它與已處理的錄製一起移動到您希望檢查錄製的主機上,然後將封存解壓縮到 ~/.debug。然後您可以像平常一樣使用 perf report -i perf.jitted.data。
如果您收到類似以下的錯誤訊息
perf: 'archive' 不是 perf 命令。請參閱 'perf --help'。
那麼您的 perf 版本太舊了,您應該改用 這個 bash 腳本。
perf 提示和技巧
您可以使用 perf 執行許多整潔的操作。以下是一些我們認為有用的選項列表
perf report --no-children不在呼叫中包含所有子項的累計。perf report --call-graph callee展開函式呼叫時顯示被呼叫者,而不是呼叫者。perf report提供「failed to process sample」和/或「failed to process type: 68」這可能表示您正在執行有錯誤的 perf 版本。當使用核心版本 4 執行 Ubuntu 18.04 時,我們遇到了這種情況。如果您更新到 Ubuntu 20.04 或使用核心版本 5 的 Ubuntu 18.04,問題應該會消失。
常見問題
我如何知道我正在執行啟用 JIT 的 Erlang?
當您啟動時,您將會在 shell 中看到包含 [jit] 的橫幅。您也可以使用 erlang:system_info(emu_flavor) 來檢查風味,它應該是 jit。
在建置 Erlang/OTP 時,您不會取得 JIT 的兩個主要原因。
- 您沒有為 x86 或 ARM 建置 64 位元模擬器
- 您沒有支援 C++-17 的 C++ 編譯器
如果您執行 ./configure --enable-jit,當它發現您的系統無法建置 JIT 時,configure 將會中止。
解譯器是否仍然可用?
是的,如果您願意,您仍然可以建置解譯器。實際上,它是在 BeamAsm 尚無法運作的平台上使用的。您可以將 --disable-jit 傳遞給 configure 來完全停用 BeamAsm。或者,您可以使用 make FLAVOR=emu 建置解譯器,然後使用 erl -emu_flavor emu 執行它。
可以同時使用 JIT 和解譯器。
與解譯器相比,我應該從 BeamAsm 獲得多少加速?
這很大程度取決於你的應用程式做什麼。可能完全沒有差異,也可能快到四倍之多。
BeamAsm 盡力不讓效能比直譯器慢,但有時還是可能發生。其中一種情況可能是生命週期非常短的小腳本。如果你遇到任何這種情況,請在 Erlang/OTP 的錯誤追蹤器上開啟一個錯誤報告。
是否有可能在其他 CPU 架構上加入 BeamAsm 的支援?
任何新的架構也需要在組譯器中支援。由於我們使用 asmjit 來做到這一點,這意味著我們需要在 asmjit 中獲得支援。BeamAsm 使用相對較少的指令(主要是 mov、jmp、cmp、sub、add),因此不需要完全支援所有指令。
另一種方法是不在新架構上使用 asmjit,而是使用其他方法在載入時組譯程式碼。
是否有可能在其他作業系統上加入 BeamAsm 的支援?
如果作業系統支援將記憶體映射為可執行檔,那麼新增一個執行 x86-64 或 aarch64 的新作業系統應該不需要任何大的改動。如果作業系統使用的 ABI 不受支援,也必須進行與呼叫 C 函數相關的變更。
作為參考,我們花了約 2-3 週的時間來實作 Windows 的支援,以及約三個月的時間來完成 aarch64 的移植。